Did Anthropic Just Leak Claude Opus 5? Mystery “Honeycomb” Model Sparks Launch Frenzy
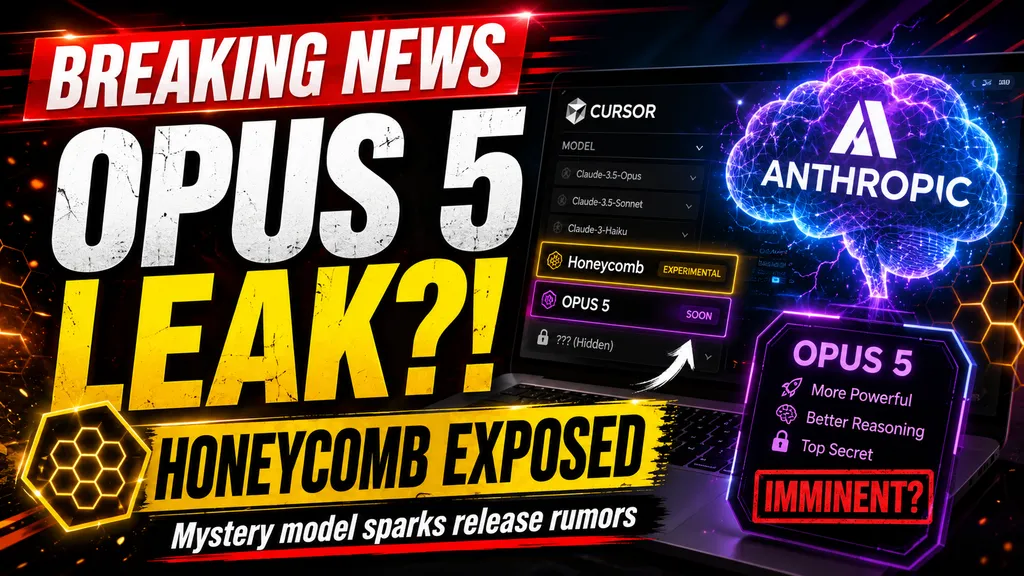
**Anthropic may be preparing to unleash its next heavyweight AI model—and the company might have accidentally allowed developers to take it for an early test drive.** The AI rumor mill is officially in overdrive after a mysterious experimental model named **“Claude Honeycomb EAP”** briefly appeared inside the Cursor coding platform before suddenly vanishing. Now developers are asking the billion-dollar question: **Was Honeycomb actually Claude Opus 5 hiding behind a secret codename?** Anthropic has not officially announced Claude Opus 5, meaning there is currently no confirmation that Honeycomb and Opus 5 are the same model—or that an Opus 5 release...